 Traditional methods of identifying phenotypes over varied networks of electronic health record (EHR) databases is challenging. The recently published “Facilitating Phenotype Transfer Using A Common Data Model” paper in the Journal of Biomedical Informatics demonstrated success in creating a systematic process for sharing disease definitions—known as phenotypes—across a network using the Observational Health Data Sciences and Informatics (OHDSI) OMOP Common Data Model, which could lead to dramatic improvements in the ability to study diseases in the future.
Traditional methods of identifying phenotypes over varied networks of electronic health record (EHR) databases is challenging. The recently published “Facilitating Phenotype Transfer Using A Common Data Model” paper in the Journal of Biomedical Informatics demonstrated success in creating a systematic process for sharing disease definitions—known as phenotypes—across a network using the Observational Health Data Sciences and Informatics (OHDSI) OMOP Common Data Model, which could lead to dramatic improvements in the ability to study diseases in the future.
George Hripcsak, MD, MS, the co-PI of the OHDSI Coordinating Center at Columbia University, served as lead author for a paper that demonstrated an efficient alternative to phenotype sharing that allows for rapid exchange and execution across different medical centers, improving the speed and reproducibility of the research process.
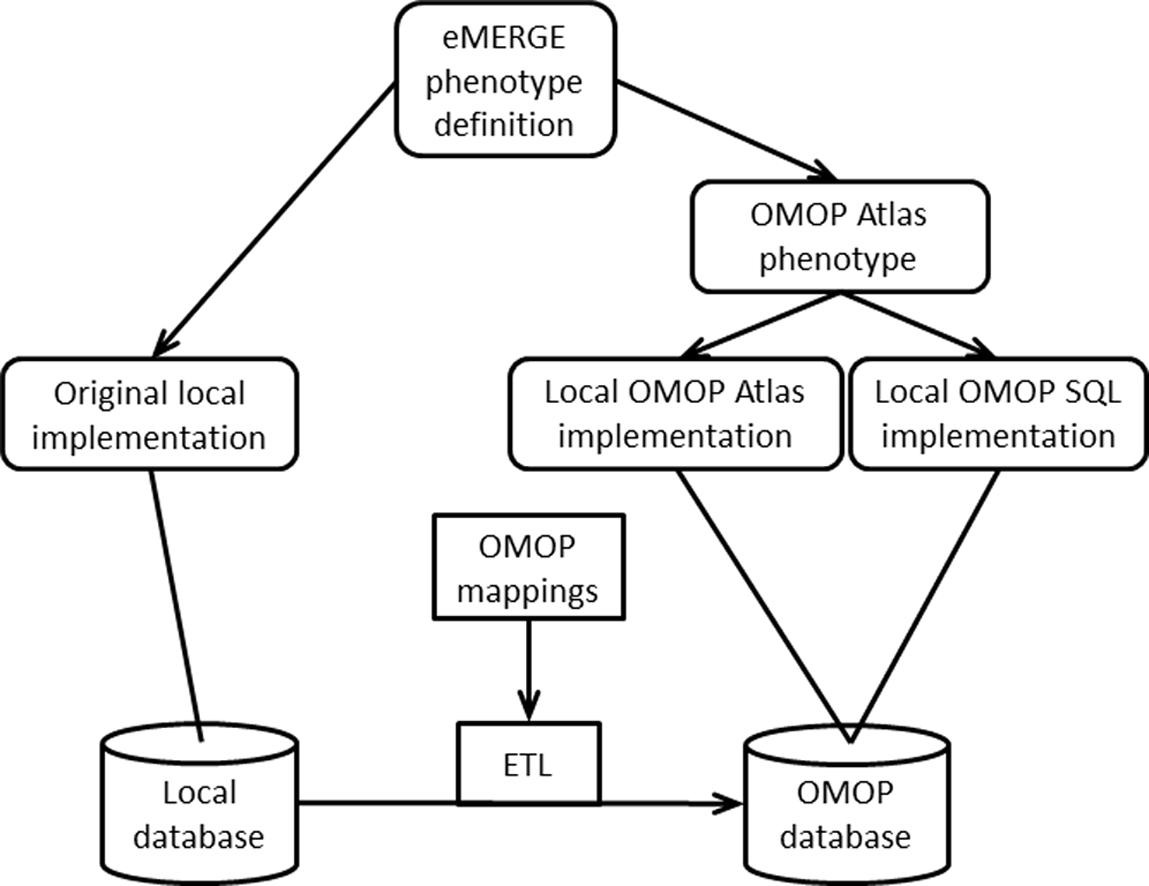
The Electronic Medical Records and Genomics (eMERGE) Network converted its databases to the OMOP Common Data Model, allowing for efficient phenotype searches throughout its complete network. It allows multiple research studies to occur without reimplementation of conversion or misinterpretation of phenotype definition. Queries, which often take weeks for manual local reimplementation, were completed within a day, and some reached 100% agreement.
The degree of agreement varied due to issues with the phenotype, data changes or database issues, but the study showed potential breakthrough for greater efficiency in the study of human disease through a common data model.
This study showcased the power of developing one standardized analytic tool and applying it across a network of 10 different observational databases through a shared community adoption of the OMOP common data model.